Подробно теорема Байеса излагается в отдельной статье . Это замечательная работа, но в ней 15 000 слов. В этом же переводе статьи от Kalid Azad кратко объясняется самая суть теоремы.
- Результаты исследований и испытаний – это не события. Существует метод диагностики рака, а есть само событие - наличие заболевания. Алгоритм проверяет, содержит ли письмо спам, но событие (на почту действительно пришел спам) нужно рассматривать отдельно от результата его работы.
- В результатах испытаний бывают ошибки. Часто наши методы исследований выявляют то, чего нет (ложноположительный результат), и не выявляют то, что есть (ложноотрицательный результат).
- С помощью испытаний мы получаем вероятности определенного исхода. Мы слишком часто рассматриваем результаты испытания сами по себе и не учитываем ошибки метода.
- Ложноположительные результаты искажают картину. Предположим, что вы пытаетесь выявить какой-то очень редкий феномен (1 случай на 1000000). Даже если ваш метод точен, вероятнее всего, его положительный результат будет на самом деле ложноположительным.
- Работать удобнее с натуральными числами. Лучше сказать: 100 из 10000, а не 1%. При таком подходе будет меньше ошибок, особенно при умножении. Допустим, нам нужно дальше работать с этим 1%. Рассуждения в процентах неуклюжи: «в 80% случаев из 1% получили положительный исход». Гораздо легче информация воспринимается так: «в 80 случаях из 100 наблюдали положительный исход».
- Даже в науке любой факт - это всего лишь результат применения какого-либо метода. С философской точки зрения научный эксперимент – это всего лишь испытание с вероятной ошибкой. Есть метод, выявляющий химическое вещество или какой-нибудь феномен, и есть само событие - присутствие этого феномена. Наши методы испытаний могут дать ложный результат, а любое оборудование обладает присущей ему ошибкой.
- Если нам известна вероятность события и вероятность ложноположительных и ложноотрицательных результатов, мы можем исправить ошибки измерений.
- Теорема соотносит вероятность события с вероятностью определенного исхода. Мы можем соотнести Pr(A|X): вероятность события А, если дан исход X, и Pr(X|A): вероятность исхода X, если дано событие А.
Разберемся в методе
В статье, на которую дана ссылка в начале этого эссе, разбирается метод диагностики (маммограмма), выявляющий рак груди. Рассмотрим этот метод подробно.- 1% всех женщин болеют раком груди (и, соответственно, 99% не болеют)
- 80% маммограмм выявляют заболевание, когда оно действительно есть (и, соответственно, 20% не выявляют)
- 9,6% исследований выявляют рак, когда его нет (и, соответственно, 90,4% верно определяют отрицательный результат)
Как работать с этим данными?
- 1% женщин болеют раком груди
- если у пациентки выявили заболевание, смотрим в первую колонку: есть 80% вероятность того, что метод дал верный результат, и 20% вероятность того, что результат исследования неправильный (ложноотрицательный)
- если у пациентки заболевание не выявили, смотрим на вторую колонку. С вероятностью 9,6% можно сказать, что положительный результат исследования неверен, и с 90,4% вероятностью можно сказать, что пациентка действительно здорова.
Насколько метод точен?
Теперь разберем положительный результат теста. Какова вероятность того, что человек действительно болен: 80%, 90%, 1%?Давайте подумаем:
- Есть положительный результат. Разберем все возможные исходы: полученный результат может быть как истинным положительным, так и ложноположительным.
- Вероятность истинного положительного результата равна: вероятность заболеть, умноженная на вероятность того, что тест действительно выявил заболевание. 1% * 80% = .008
- Вероятность ложноположительного результата равна: вероятность того, что заболевания нет, умноженная на вероятность того, что метод выявил заболевание неверно. 99% * 9.6% = .09504
Какова вероятность, что человек действительно болен, если получен положительный результат маммограммы? Вероятность события - это отношение количества возможных исходов события к общему количеству всех возможных исходов.
Вероятность события = исходы события / все возможные исходы
Вероятность истинного положительного результата – .008. Вероятность положительного результата - это вероятность истинного положительного исхода + вероятность ложноположительного.
(.008 + 0.09504 = .10304)
Итак, вероятность заболевания при положительном результате исследования рассчитывается так: .008/.10304 = 0.0776. Эта величина составляет около 7.8%.
То есть положительный результат маммограммы значит только то, что вероятность наличия заболевания – 7,8%, а не 80% (последняя величина - это лишь предполагаемая точность метода). Такой результат кажется поначалу непонятным и странным, но нужно учесть: метод дает ложноположительный результат в 9,6% случаев (а это довольно много), поэтому в выборке будет много ложноположительных результатов. Для редкого заболевания большинство положительных результатов будут ложноположительными.
Давайте пробежимся глазами по таблице и попробуем интуитивно ухватить смысл теоремы. Если у нас есть 100 человек, только у одного из них есть заболевание (1%). У этого человека с 80% вероятностью метод даст положительный результат. Из оставшихся 99% у 10% будут положительные результаты, что дает нам, грубо говоря, 10 ложноположительных исходов из 100. Если мы рассмотрим все положительные результаты, то только 1 из 11 будет верным. Таким образом, если получен положительный результат, вероятность заболевания составляет 1/11.
Выше мы посчитали, что эта вероятность равна 7,8%, т.е. число на самом деле ближе к 1/13, однако здесь с помощью простого рассуждения нам удалось найти приблизительную оценку без калькулятора.
Теорема Байеса
Теперь опишем ход наших мыслей формулой, которая и называется теоремой Байеса. Эта теорема позволяет исправить результаты исследования в соответствии с искажением, которое вносят ложноположительные результаты:- Pr(A|X) = вероятность заболевания (А) при положительном результате (X). Это как раз то, что мы хотим знать: какова вероятность события в случае положительного исхода. В нашем примере она равна 7,8%.
- Pr(X|A) = вероятность положительного результата (X) в случае, когда больной действительно болен (А). В нашем случае это величина истинных положительных – 80%
- Pr(A) = вероятность заболеть (1%)
- Pr(not A) = вероятность не заболеть (99%)
- Pr(X|not A) = вероятность положительного исхода исследования в случае, если заболевания нет. Это величина ложноположительных – 9,6 %.
Pr(X) – это константа нормализации. Она сослужила нам хорошую службу: без нее положительный исход испытаний дал бы нам 80% вероятность события.
Pr(X) – это вероятность любого положительного результата, будет ли это настоящий положительный результат при исследовании больных (1%) или ложноположительный при исследовании здоровых людей (99%).
В нашем примере Pr(X) – довольно большое число, потому что велика вероятность ложноположительных результатов.
Pr(X) создает результат 7,8%, который на первый взгляд кажется противоречащим здравому смыслу.
Смысл теоремы
Мы проводим испытания, чтоб выяснить истинное положение вещей. Если наши испытания совершенны и точны, тогда вероятности испытаний и вероятности событий совпадут. Все положительные результаты будут действительно положительными, а отрицательные - отрицательными. Но мы живем в реальном мире. И в нашем мире испытания дают неверные результаты. Теорема Байеса учитывает искаженные результаты, исправляет ошибки, воссоздает генеральную совокупность и находит вероятность истинного положительного результата.Спам-фильтр
Теорема Байеса удачно применяется в спам-фильтрах.У нас есть:
- событие А - в письме спам
- результат испытания - содержание в письме определенных слов:
Фильтр берет в расчет результаты испытаний (содержание в письме определенных слов) и предсказывает, содержит ли письмо спам. Всем понятно, что, например, слово «виагра» чаще встречается в спаме, чем в обычных письмах.
Фильтр спама на основе черного списка обладает недостатками - он часто выдает ложноположительные результаты.
Спам-фильтр на основе теоремы Байеса использует взвешенный и разумный подход: он работает с вероятностями. Когда мы анализируем слова в письме, мы можем рассчитать вероятность того, что письмо - это спам, а не принимать решения по типу «да/нет». Если вероятность того, что письмо содержит спам, равна 99%, то письмо и вправду является таковым.
Со временем фильтр тренируется на все большей выборке и обновляет вероятности. Так, продвинутые фильтры, созданные на основе теоремы Байеса, проверяют множество слов подряд и используют их в качестве данных.
Дополнительные источники:
Теги: Добавить метки
Кто такой Байес? и какое отношение он имеет к менеджменту? – может последовать вполне справедливый вопрос. Пока поверьте мне на слово: это очень важно!.. и интересно (по крайней мере, мне).
В какой парадигме действуют большинство менеджеров: если я наблюдаю нечто, какие выводы могу из этого сделать? Чему учит Байес: что должно быть на самом деле, чтобы мне довелось наблюдать это нечто? Именно так развиваются все науки, и об этом пишет (цитирую по памяти): человек, у которого нет в голове теории, будет шарахаться от одной идеи к другой под воздействием различных событий (наблюдений). Не даром говорят: нет ничего более практичного, чем хорошая теория.
Пример из практики. Мой подчиненный совершает ошибку, и мой коллега (руководитель другого отдела) говорит, что надо бы оказать управленческое воздействие на нерадивого сотрудника (проще говоря, наказать/обругать). А я знаю, что этот сотрудник делает 4–5 тысяч однотипных операций в месяц, и совершает за это время не более 10 ошибок. Чувствуете различие в парадигме? Мой коллега реагирует на наблюдение, а я обладаю априорным знанием, что сотрудник допускает некоторое количество ошибок, так что еще одна не повлияла на это знание… Вот если по итогам месяца окажется, что таких ошибок, например, 15!.. Это уже станет поводом для изучения причин несоответствия стандартам.
Убедил в важности Байесовского подхода? Заинтриговал? Надеюсь, что «да». А теперь ложка дегтя. К сожалению, идеи Байеса редко даются с первого захода. Мне откровенно не повезло, так как я знакомился с этими идеями по популярной литературе, после прочтения которой оставалось много вопросов. Планируя написать заметку, я собрал всё, что ранее конспектировал по Байесу, а также изучил, что пишут в Интернете. Предлагаю вашему вниманию мое лучшее предположение на тему Введение в Байесовскую вероятность .
Вывод теоремы Байеса
Рассмотрим следующий эксперимент: мы называем любое число лежащее на отрезке и фиксируем, когда это число будет, например, между 0,1 и 0,4 (рис. 1а). Вероятность этого события равна отношению длины отрезка к общей длине отрезка , при условии, что появления чисел на отрезке равновероятны . Математически это можно записать p (0,1 <= x <= 0,4) = 0,3, или кратко р (X ) = 0,3, где р – вероятность, х – случайная величина в диапазоне , Х – случайная величина в диапазоне . То есть, вероятность попадания в отрезок равна 30%.

Рис. 1. Графическая интерпретация вероятностей
Теперь рассмотрим квадрат x (рис. 1б). Допустим, мы должны называть пары чисел (x , y ), каждое из которых больше нуля и меньше единицы. Вероятность того, что x (первое число) будет в пределах отрезка (синяя область 1), равна отношению площади синей области к площади всего квадрата, то есть (0,4 – 0,1) * (1 – 0) / (1 * 1) = 0,3, то есть те же 30%. Вероятность того, что y находится внутри отрезка (зеленая область 2) равна отношению площади зеленой области к площади всего квадрата p (0,5 <= y <= 0,7) = 0,2, или кратко р (Y ) = 0,2.
Что можно узнать о значениях одновременно x и y . Например, какова вероятность того, что одновременно x и y находятся в соответствующих заданных отрезках? Для этого надо посчитать отношение площади области 3 (пересечения зеленой и синей полос) к площади всего квадрата: p (X , Y ) = (0,4 – 0,1) * (0,7 – 0,5) / (1 * 1) = 0,06.
А теперь допустим мы хотим знать какова вероятность того, что y находится в интервале , если x уже находится в интервале . То есть фактически у нас есть фильтр и когда мы называем пары (x , y ), то мы сразу отбрасывает те пары, которые не удовлетворяют условию нахождения x в заданном интервале, а потом из отфильтрованных пар мы считаем те, для которых y удовлетворяет нашему условию и считаем вероятность как отношение количества пар, для которых y лежит в вышеупомянутом отрезке к общему количеству отфильтрованных пар (то есть для которых x лежит в отрезке ). Мы можем записать эту вероятность как p (Y |X у х попал в диапазоне ». Очевидно, что эта вероятность равна отношению площади области 3 к площади синей области 1. Площадь области 3 равна (0,4 – 0,1) * (0,7 – 0,5) = 0,06, а площадь синей области 1 (0,4 – 0,1) * (1 – 0) = 0,3, тогда их отношение равно 0,06 / 0,3 = 0,2. Другими словами, вероятность нахождения y на отрезке при условии, что x принадлежит отрезку p (Y |X ) = 0,2.
В предыдущем абзаце мы фактически сформулировали тождество: p (Y |X ) = p (X , Y ) / p(X ). Читается: «вероятность попадания у в диапазон , при условии, что х попал в диапазон , равна отношению вероятности одновременного попадания х в диапазон и у в диапазон , к вероятности попадания х в диапазон ».
По аналогии рассмотрим вероятность p (X |Y ). Мы называем пары (x , y ) и фильтруем те, для которых y лежит между 0,5 и 0,7, тогда вероятность того, что x находится в отрезке при условии, что y принадлежит отрезку равна отношению площади области 3 к площади зеленой области 2: p (X |Y ) = p (X , Y ) / p (Y ).
Заметим, что вероятности p (X , Y ) и p (Y, Х ) равны, и обе равны отношению площади зоны 3 к площади всего квадрата, а вот вероятности p (Y |X ) и p (X |Y ) не равны; при этом вероятность p (Y |X ) равна отношению площади области 3 к области 1, а p (X |Y ) – области 3 к области 2. Заметим также, что p (X , Y ) часто обозначают как p (X &Y ).
Итак, мы ввели два определения: p (Y |X ) = p (X , Y ) / p(X ) и p (X |Y ) = p (X , Y ) / p (Y )
Перепишем эти равенства виде: p (X , Y ) = p (Y |X ) * p(X ) и p (X , Y ) = p (X |Y ) * p (Y )
Поскольку левые части равны, равны и правые: p (Y |X ) * p(X ) = p (X |Y ) * p (Y )
Или мы можем переписать последнее равенство в виде:

Это и есть теорема Байеса!
Неужели столь несложные (почти тавтологические) преобразования рождают великую теорему!? Не спешите с выводами. Давайте еще раз проговорим, что же мы получили. Имелась некая исходная (априорная) вероятность р (Х), того, что случайная величина х равномерно распределенная на отрезке попадает в диапазон Х . Произошло некое событие Y , в результате которого мы получили апостериорную вероятность той же самой случайной величины х : р (Х|Y), и эта вероятность отличается от р (Х) на коэффициент . Событие Y называется свидетельством, в большей или меньшей степени подтверждающим или опровергающим Х . Указанный коэффициент иногда называют мощностью свидетельства . Чем мощнее свидетельство, тем больше факт наблюдения Y изменяет априорную вероятность, тем больше апостериорная вероятность отличается от априорной. Если свидетельство слабое, апостериорная вероятность почти равна априорной.
Формула Байеса для дискретных случайных величин
В предыдущем разделе мы вывели формулу Байеса для непрерывных случайных величин х и y, определенных на отрезке . Рассмотрим пример с дискретными случайными величинами, принимающими каждая по два возможных значения. В ходе проведения плановых медицинских осмотров установлено, что в сорокалетнем возрасте 1% женщин болеет раком молочной железы. 80% женщин больных раком получают положительные результаты маммографии. 9,6% здоровых женщин также получают положительные результаты маммографии. В ходе проведения осмотра женщина данной возрастной группы получила положительный результат маммографии. Какова вероятность того, что у неё на самом деле рак молочной железы?
Ход рассуждений/вычислений следующий. Из 1% больных раком маммография даст 80% положительных результатов = 1%*80% = 0,8%. Из 99% здоровых женщин маммография даст 9,6% положительных результатов = 99%*9,6% = 9,504%. Итого из 10,304% (9,504% + 0,8%) с положительными результатами маммографии, только 0,8% больных, а остальные 9,504% здоровых. Таким образом, вероятность того, что при положительном результате маммографии женщина больна раком составляет 0,8%/10,304% = 7,764%. А вы думали, что 80% или около того?
В нашем примере формула Байеса принимает следующий вид:
Давайте еще раз проговорим «физический» смысл этой формулы. Х – случайная величина (диагноз), принимающая значения: Х 1 – болен и Х 2 – здоров; Y – случайная величина (результат измерения –маммографии), принимающая значения: Y 1 – положительный результат и Y 2 – отрицательный результат; р(Х 1) – вероятность болезни до проведения маммографии (априорная вероятность), равная 1%; р(Y 1 |X 1 ) – вероятность положительного результата в случае, если пациентка больна (условная вероятность, так как она должна быть задана в условиях задачи), равная 80%; р(Y 1 |X 2 ) – вероятность положительного результата в случае, если пациентка здорова (также условная вероятность), равная 9,6%; р(Х 2) – вероятность того, что пациентка здорова до проведения маммографии (априорная вероятность), равная 99%; р(Х 1 |Y 1 ) – вероятность того, что пациентка больна, при условии положительного результата маммографии (апостериорная вероятность).
Видно, что апостериорная вероятность (то, что мы ищем) пропорциональна априорной вероятности (исходной) с несколько более сложным коэффициентом  . Подчеркну еще раз. На мой взгляд, это фундаментальный аспект Байесовского подхода. Измерение (Y
) добавило некоторое количество информации к первоначально имевшейся (априорной), что уточнило наше знание об объекте.
. Подчеркну еще раз. На мой взгляд, это фундаментальный аспект Байесовского подхода. Измерение (Y
) добавило некоторое количество информации к первоначально имевшейся (априорной), что уточнило наше знание об объекте.
Примеры
Для закрепления пройденного материала попробуйте решить несколько задач.
Пример 1. Имеется 3 урны; в первой 3 белых шара и 1 черный; во второй - 2 белых шара и 3 черных; в третьей - 3 белых шара. Некто подходит наугад к одной из урн и вынимает из нее 1 шар. Этот шар оказался белым. Найдите апостериорные вероятности того, что шар вынут из 1-й, 2-й, 3-й урны.
Решение. У нас есть три гипотезы: Н 1 = {выбрана первая урна), Н 2 = {выбрана вторая урна}, Н 3 = {выбрана третья урна}. Так как урна выбирается наугад, то априорные вероятности гипотез равны: Р(Н 1) = Р(Н 2) = Р(Н 3) = 1/3.
В результате опыта появилось событие А = {из выбранной урны вынут белый шар}. Условные вероятности события А при гипотезах Н 1 , Н 2 , Н 3: Р(A|Н 1) = 3/4, Р(A|Н 2) = 2/5, Р(A|Н 3) = 1. Например, первое равенство читается так: «вероятность вынуть белый шар, если выбрана первая урна равна 3/4 (так как всего шаров в первой урне 4, а белых из них – 3)».
Применяя формулу Бейеса, находим апостериорные вероятности гипотез:

Таким образом, в свете информации о появлении события А вероятности гипотез изменились: наиболее вероятной стала гипотеза Н 3 , наименее вероятной - гипотеза Н 2 .
Пример 2. Два стрелка независимо друг от друга стреляют по одной и той же мишени, делая каждый по одному выстрелу. Вероятность попадания в мишень для первого стрелка равна 0,8, для второго - 0,4. После стрельбы в мишени обнаружена одна пробоина. Найти вероятность того, что эта пробоина принадлежит первому стрелку (Исход {обе пробоины совпали} отбрасываем, как ничтожно маловероятный).
Решение. До опыта возможны следующие гипотезы: Н 1 = {ни первый, ни второй стрелки не попадут}, Н 2 = {оба стрелка попадут}, H 3 - {первый стрелок попадет, а второй - нет}, H 4 = {первый стрелок не попадет, а второй попадет). Априорные вероятности гипотез:
Р(H 1) = 0,2*0,6 = 0,12; Р(H 2) = 0,8*0,4 = 0,32; Р (H 3) = 0,8*0,6 = 0,48; Р(H 4) = 0,2*0,4 = 0,08.
Условные вероятности наблюденного события А = {в мишени одна пробоина} при этих гипотезах равны: P(A|H 1) = P(A|H 2) = 0; P(A|H 3) = P(A|H 4) = 1
После опыта гипотезы H 1 и H 2 становятся невозможными, а апостериорные вероятности гипотез H 3 , и H 4 по формуле Бейеса будут:

Байес против спама
Формула Байеса нашла широкое применение в разработке спам-фильтров. Предположим, вы хотите обучить компьютер определять, какие из писем являются спамом. Будем исходить из словаря и словосочетаний, используя байесовские оценки. Создадим вначале пространство гипотез. Пусть относительно любого письма у нас есть 2 гипотезы: H A – это спам, H B – это не спам, а нормальное, нужное, письмо.
Вначале «обучим» нашу будущую систему борьбы со спамом. Возьмем все имеющиеся у нас письма и разделим их на две «кучи» по 10 писем. В одну отложим спам-письма и назовем ее кучей H A , в другую – нужную корреспонденцию и назовем ее кучей H B . Теперь посмотрим: какие слова и словосочетания встречаются в спам- и нужных письмах и с какой частотой? Эти слова и словосочетания назовем свидетельствами и обозначим E 1 , E 2 … Выясняется, что общеупотребительные слова (например, слова «как», «твой») в кучах H A и H B встречаются примерно с одинаковой частотой. Таким образом, наличие этих слов в письме ничего не говорит нам о том, к какой куче его отнести (слабое свидетельство). Присвоим этим словам нейтральное значение оценки вероятности «спамности», скажем, 0,5.
Пусть словосочетание «разговорный английский» встречается всего в 10 письмах, причем чаще в спам-письмах (например, в 7 спам-письмах из всех 10), чем в нужных (в 3 из 10). Поставим этому словосочетанию для спама более высокую оценку 7/10, а для нормальных писем более низкую: 3/10. И наоборот, выяснилось, что слово «дружище» чаще встречалось в нормальных письмах (6 из 10). И вот мы получили коротенькое письмо: «Дружище! Как твой разговорный английский?» . Попробуем оценить его «спамность». Общие оценки P(H A), P(H B) принадлежности письма к каждой куче поставим, воспользовавшись несколько упрощенной формулой Байеса и нашими приблизительными оценками:
P(H A) = A/(A+B), где А = p a1 *p a2 *…*p an , B = p b1 *p b2 *…*p b n = (1 – p a1)*(1 – p a2)*… *(1 – p an).
Таблица 1. Упрощенная (и неполная) Байес-оценка письма

Таким образом, наше гипотетическое письмо получило оценку вероятности принадлежности с акцентом в сторону «спамности». Можем ли мы принять решение о том, чтобы бросить письмо в одну из куч? Выставим пороги принятия решений:
- Будем считать, что письмо принадлежит куче H i , если P(H i) ≥ T.
- Письмо не принадлежит куче, если P(H i) ≤ L.
- Если же L ≤ P(H i) ≤ T, то нельзя принять никакого решения.
Можно принять T = 0,95 и L = 0,05. Поскольку для рассматриваемого письма и 0,05 < P(H A) < 0,95, и 0,05 < P(H В) < 0,95, то мы не сможем принять решение, куда отнести данное письмо: к спаму (H A) или к нужным письмам (H B). Можно ли улучшить оценку, используя больше информации?
Да. Давайте вычислим оценку для каждого свидетельства другим способом, так, как это, собственно, и предложил Байес. Пусть:
F a – это общее количество писем спама;
F ai – это количество писем со свидетельством i в куче спама;
F b – это общее количество нужных писем;
F bi – это количество писем со свидетельством i в куче нужных (релевантных) писем.
Тогда: p ai = F ai /F a , p bi = F bi /F b . P(H A) = A/(A+B), P(H B) = B/(A+B), где А = p a1 *p a2 *…*p an , B = p b1 *p b2 *…*p b n
Обратите внимание – оценки слов-свидетельств p ai и p bi стали объективными и их можно вычислять без участия человека.
Таблица 2. Более точная (но неполная) Байес-оценка по наличным признакам из письма

Мы получили вполне определенный результат – с большим перевесом с вероятностью письмо можно отнести к нужным письмам, поскольку P(H B) = 0,997 > T = 0,95. Почему результат изменился? Потому, что мы использовали больше информации – мы учли количество писем в каждой из куч и, кстати, гораздо более корректно определили оценки p ai и p bi . Определили их так, как это сделано у самого Байеса, вычислив условные вероятности. Другими словами, p a3 – это вероятность появления в письме слова «дружище» при условии того, что это письмо уже принадлежит спам-куче H A . Результат не заставил себя ждать – кажется, мы можем принять решение с большей определенностью.
Байес против корпоративного мошенничества
Любопытное применение Байесовского подхода описал MAGNUS8 .
В моем текущем проекте (ИС для выявления мошенничества на производственном предприятии) используется формула Байеса для определения вероятности фрода (мошенничества) при наличии/отсутствии нескольких фактов, косвенно свидетельствующих в пользу гипотезы о возможности совершения фрода. Алгоритм самообучаем (с обратной связью), т.е. пересчитывает свои коэффициенты (условные вероятности) при фактическом подтверждении или неподтверждении фрода при проверке службой экономической безопасности.
Стоит, наверное, сказать, что подобные методы при проектировании алгоритмов требуют достаточно высокой математической культуры разработчика, т.к. малейшая ошибка в выводе и/или реализации вычислительных формул сведет на нет и дискредитирует весь метод. Вероятностные методы особенно этим грешат, поскольку мышление человека не приспособлено для работы с вероятностными категориями и, соответственно, отсутствует «наглядность» и понимание «физического смысла» промежуточных и итоговых вероятностных параметров. Такое понимание есть лишь для базовых понятий теории вероятностей, а дальше нужно лишь очень аккуратно комбинировать и выводить сложные вещи по законам теории вероятностей - здравый смысл для композитных объектов уже не поможет. С этим, в частности, связаны достаточно серьезные методологические баталии, проходящие на страницах современных книг по философии вероятности, а также большое количество софизмов, парадоксов и задачек-курьезов по этой теме.
Еще один нюанс, с которым пришлось столкнуться - к сожалению, практически все мало-мальски ПОЛЕЗНОЕ НА ПРАКТИКЕ на эту тему написано на английском языке. В русскоязычных источниках в основном только общеизвестная теория с демонстрационными примерами лишь для самых примитивных случаев.
Полностью соглашусь с последним замечанием. Например, Google при попытке найти что-то типа «книги Байесовская вероятность», ничего внятного не выдал. Правда, сообщил, что книгу с байесовской статистикой запретили в Китае . (Профессор статистики Эндрю Гельман сообщил в блоге Колумбийского университета, что его книгу «Анализ данных с помощью регрессии и многоуровневых/иерархических моделей» запретили публиковать в Китае. Тамошнее издательство сообщило, что «книга не получила одобрения властей из-за различных политически чувствительных материалов в тексте».) Интересно, не аналогичная ли причина привела к отсутствию книг по Байесовской вероятности в России?
Консерватизм в процессе обработки информации человеком
Вероятности определяют степень неопределенности. Вероятность, как согласно Байесу, так и нашей интуиции, составляет просто число между нулем и тем, что представляет степень, для которой несколько идеализированный человек считает, что утверждение верно. Причина, по которой человек несколько идеализирован, состоит в том, что сумма его вероятностей для двух взаимно исключающих событий должна равняться его вероятности того, что произойдет любое из этих событий. Свойство аддитивности имеет такие последствия, что мало реальных людей могут соответствовать им всем.
Теорема Байеса – это тривиальное последствие свойства аддитивности, бесспорное и согласованное для всех сторонников вероятностей, как Байеса, так и других. Один их способов написать это следующий. Если Р(H А |D) – последующая вероятность того, что гипотеза А была после того, как данная величина D наблюдалась, Р(H А) – его априорная вероятность до того, как наблюдалась данная величина D, Р(D|H А) – вероятность того, что данная величина D будет наблюдаться, если верно Н А, а Р(D) – безусловная вероятность данной величины D, то
(1) Р(H А |D) = Р(D|H А) * Р(H А) / Р(D)
Р(D) лучше всего рассматривать как нормализующую константу, заставляющую апостериорные вероятности составить в целом единицу по исчерпывающему набору взаимно исключающих гипотез, которые рассматриваются. Если ее необходимо подсчитать, она может быть такой:
Но чаще Р(D) устраняется, а не подсчитывается. Удобный способ устранять ее состоит в том, чтобы преобразовать теорему Байеса в форму отношения вероятность–шансы.
Рассмотрим другую гипотезу, Н B , взаимно исключающую Н А, и изменим мнение о ней на основе той же самой данной величины, которая изменила ваше мнение о Н А. Теорема Байеса говорит, что
(2) Р(H B |D) = Р(D|H B) * Р(H B) / Р(D)
Теперь разделим Уравнение 1 на Уравнение 2; результат будет таким:

где Ω 1 – апостериорные шансы в пользу Н А через H B , Ω 0 – априорные шансы, a L – количество, знакомое статистикам как отношение вероятности. Уравнение 3 – это такая же соответствующая версия теоремы Байеса как и Уравнение 1, и часто значительно более полезная особенно для экспериментов, с участием гипотез. Сторонники Байеса утверждают, что теорема Байеса – формально оптимальное правило о том, как пересматривать мнения в свете новых данных.
Мы интересуемся сравнением идеального поведения, определенного теоремой Байеса, с фактическим поведением людей. Чтобы дать вам некоторое представление о том, что это означает, давайте попробуем провести эксперимент с вами как с испытуемым. Эта сумка содержит 1000 покерных фишек. У меня две такие сумки, причем в одной 700 красных и 300 синих фишек, а в другой 300 красных и 700 синих. Я подбросил монету, чтобы определить, какую использовать. Таким образом, если наши мнения совпадают, ваша вероятность в настоящее время, что выпадет сумка, в которой больше красных фишек – 0,5. Теперь, Вы наугад составляете выборку с возвращением после каждой фишки. В 12 фишках вы получаете 8 красных и 4 синих. Теперь, на основе всего, что вы знаете, какова вероятность того, что выпала сумка, где больше красных? Ясно, что она выше, чем 0,5. Пожалуйста, не продолжайте читать, пока вы не записали вашу оценку.
Если вы похожи на типичного испытуемого, ваша оценка попала в диапазон от 0,7 до 0,8. Если бы мы проделали соответствующее вычисление, тем не менее, ответ был бы 0,97. Действительно очень редко человек, которому предварительно не продемонстрировали влияние консерватизма, приходит к такой высокой оценке, даже если он был знаком с теоремой Байеса.
Если доля красных фишек в сумке – р , то вероятность получения r красных фишек и (n – r ) синих в n выборках с возвращением – p r (1– p) n– r . Так, в типичном эксперименте с сумкой и покерными фишками, если Н A означает, что доля красных фишек составляет р А и Н B – означает, что доля составляет р B , тогда отношение вероятности:

При применении формулы Байеса необходимо учитывать только вероятность фактического наблюдения, а, не вероятности других наблюдений, которые он, возможно, сделал бы, но не сделал. Этот принцип имеет широкое воздействие на все статистические и нестатистические применения теоремы Байеса; это самый важный технический инструмент размышления Байеса.
Байесовская революция
Ваши друзья и коллеги разговаривают о чем-то, под названием «Теорема Байеса» или «Байесовское правило», или о чем-то под названием байесовское мышление. Они действительно заинтересованы в этом, так что вы лезете в интернет и находите страницу о теореме Байеса и… Это уравнение. И все… Почему математическая концепция порождает в умах такой энтузиазм? Что за «байесианская революция» происходит в среде учёных, причем утверждается, что даже сам экспериментальный подход может быть описан, как её частный случай? В чём секрет, который знают последователи Байеса? Что за свет они видят?
Байесовская революция в науке произошла не потому, что все больше и больше когнитивных ученых внезапно начали замечать, что ментальные явления имеют байесовскую структуру; не потому, что ученые в каждой области начали использовать байесовский метод; но потому, что наука сама по себе является частным случаем теоремы Байеса; экспериментальное свидетельство есть байесовское свидетельство. Байесовские революционеры утверждают, что когда вы выполняете эксперимент и получаете свидетельство, которое «подтверждает» или «опровергает» вашу теорию, это подтверждение или опровержение происходит по байесовским правилам. Для примера, вы должны принимать во внимание не только то, что ваша теория может объяснить явление, но и то, что есть другие возможные объяснения, которые также могут предсказать это явление.
Ранее, наиболее популярной философией науки была – старая философия, которая была смещена байесовской революцией. Идея Карла Поппера, что теории могут быть полностью фальсифицированы, однако никогда не могут быть полностью подтверждены, это еще один частный случай байесовских правил; если p(X|A) ≈ 1 – если теория делает верные предсказания, тогда наблюдение ~X очень сильно фальсифицирует А. С другой стороны, если p(X|A) ≈ 1 и мы наблюдаем Х, это не очень сильно подтверждает теорию; возможно какое-то другое условие В, такое что p(X|B) ≈ 1, и при котором наблюдение Х не свидетельствует в пользу А но свидетельствует в пользу В. Для наблюдения Х определенно подтверждающего А, мы должны были бы знать не то, что p(X|A) ≈ 1, а что p(X|~A) ≈ 0, что мы не можем знать, поскольку мы не можем рассматривать все возможные альтернативные объяснения. Например, когда эйнштейновская теория общей относительности превзошла ньютоновскую хорошо подтверждаемую теорию гравитации, это сделало все предсказания ньютоновской теории частным случаем предсказаний эйнштейновской.
Похожим образом, попперовское заявление, что идея должна быть фальсифицируема может быть интерпретировано как манифестация байесовского правила о сохранении вероятности; если результат Х является положительным свидетельством для теории, тогда результат ~Х должен опровергать теорию в каком-то объеме. Если вы пытаетесь интерпретировать оба Х и ~Х как «подтверждающие» теорию, байесовские правила говорят, что это невозможно! Чтобы увеличить вероятность теории вы должны подвергнуть ее тестам, которые потенциально могут снизить ее вероятность; это не просто правило, чтобы выявлять шарлатанов в науке, но следствие из теоремы байесовской вероятности. С другой стороны, идея Поппера, что нужна только фальсификация и не нужно подтверждение является неверной. Теорема Байеса показывает, что фальсификация это очень сильное свидетельство, по сравнению с подтверждением, но фальсификация все еще вероятностна по своей природе; она не управляется фундаментально другими правилами и не отличается в этом от подтверждения, как утверждает Поппер.
Таким образом, мы обнаруживаем, что многие явления в когнитивных науках, плюс статистические методы, используемые учеными, плюс научный метод сам по себе – все они являются частными случаями теоремы Байеса. В этом и состоит Байесовская революция.
Добро пожаловать в Байесовский Заговор!
Литература по Байесовской вероятности
2. Очень много различных применений Байеса описывает нобелевский лауреат по экономике Канеман (со товарищи) в замечательной книге . Только в моем кратком конспекте этой очень большой книги я насчитал 27 упоминаний имени пресвитерианского священника. Минимум формул. (.. Мне очень понравилась. Правда, сложноватая, много математики (а куда без нее), но отдельные главы (например, глава 4. Информация), явно по теме. Советую всем. Даже, если математика для вас сложна, читайте через строку, пропуская математику, и выуживая полезные зерна…
14. (дополнение от 15 января 2017 г. ) , глава из книги Тони Крилли. 50 идей, о которых нужно знать. Математика.
Физик Нобелевский лауреат Ричарда Фейнмана, отзываясь об одном философе с особо большим самомнением, как-то сказал: «Меня раздражает вовсе не философия как наука, а та помпезность, которая создана вокруг нее. Если бы только философы могли сами над собой посмеяться! Если бы только они могли сказать: «Я говорю, что это вот так, а Фон Лейпциг считал, что это по-другому, а ведь он тоже кое-что в этом смыслит». Если бы только они не забывали пояснить, что это всего лишь их .
Краткая теория
Если событие наступает только при условии появления одного из событий образующих полную группу несовместных событий, то равна сумме произведений вероятностей каждого из событий на соответствующую условную вероятность кошелек .
При этом события называются гипотезами, а вероятности – априорными. Эта формула называется формулой полной вероятности.
Формула Байеса применяется при решении практических задач, когда событие , появляющееся совместно с каким-либо из событий образующих полную группу событий произошло и требуется провести количественную переоценку вероятностей гипотез . Априорные (до опыта) вероятности известны. Требуется вычислить апостериорные (после опыта) вероятности, т.е. по существу нужно найти условные вероятности . Формула Байеса выглядит так:
Пример решения задачи
Условие задачи 1
На фабрике станки 1,2 и 3 производят соответственно 20%, 35% и 45% всех деталей. В их продукции брак составляет соответственно 6%, 4%, 2%. Какова вероятность того, что случайно выбранное изделие оказалось дефектным? Какова вероятность того, что оно было произведено: а) станком 1; б) станком 2; в) станком 3?
Решение задачи 1
Обозначим через событие, состоящее в том, что стандартное изделие оказалось дефектным.
Событие может произойти только при условии наступления одного из трех событий:
Изделие произведено на станке 1;
Изделие произведено на станке 2;
Изделие произведено на станке 3;
Запишем условные вероятности:
Формула полной вероятности
Если событие может произойти только при выполнении одного из событий , которые образуютполную группу несовместных событий, то вероятность события вычисляется по формуле
По формуле полной вероятности находим вероятность события :
Формула Байеса
Формула Байеса позволяет «переставить причину и следствие»: по известному факту события вычислить вероятность того, что оно было вызвано данной причиной.
Вероятность того, что дефектное изделие изготовлено на станке 1:
Вероятность того, что дефектное изделие изготовлено на станке 2:
Вероятность того, что дефектное изделие изготовлено на станке 3:
Условие задачи 2
Группа состоит из 1 отличника, 5 хорошо успевающих студентов и 14 студентов, успевающих посредственно. Отличник отвечает на 5 и 4 с равной вероятностью, хорошист отвечает на 5, 4 и 3 с равной вероятностью, и посредственно успевающий студент отвечает на 4,3 и 2 с равной вероятностью. Случайно выбранный студент ответил на 4. Какова вероятность того, что был вызван посредственно успевающий студент?
Решение задачи 2
Гипотезы и условные вероятности
Возможны следующие гипотезы:
Отвечал отличник;
Отвечал хорошист;
–отвечал посредственно занимающийся студент;
Пусть событие -студент получит 4.
Условные вероятности:
Ответ:
Дано определение геометрической вероятности и подробно рассмотрена широко известная задача о встрече.
Начнем с примера. В урне, стоящей перед вами, с равной вероятностью могут быть (1) два белых шара, (2) один белый и один черный, (3) два черных. Вы тащите шар, и он оказывается белым. Как теперь вы оцените вероятность этих трех вариантов (гипотез)? Очевидно, что вероятность гипотезы (3) с двумя черными шарами = 0. А вот как подсчитать вероятности двух оставшихся гипотез!? Это позволяет сделать формула Байеса, которая в нашем случае имеет вид (номер формулы соответствует номеру проверяемой гипотезы):
Скачать заметку в формате или
х – случайная величина (гипотеза), принимающая значения: х 1 – два белых, х 2 – один белый, один черный; х 3 – два черных; у – случайная величина (событие), принимающая значения: у 1 – вытащен белый шар и у 2 – вытащен чёрный шар; Р(х 1) – вероятность первой гипотезы до вытаскивания шара (априорная вероятность или вероятность до опыта) = 1/3; Р(х 2) – вероятность второй гипотезы до вытаскивания шара = 1/3; Р(х 3) – вероятность третьей гипотезы до вытаскивания шара = 1/3; Р(у 1 |х 1) – условная вероятность вытащить белый шар, в случае, если верна первая гипотеза (шары белые) = 1; Р(у 1 |х 2) – вероятность вытащить белый шар, в случае, если верна вторая гипотеза (один шар белый, второй – черный) = ½; Р(у 1 |х 3) – вероятность вытащить белый шар, в случае, если верна третья гипотеза (оба черных) = 0; Р(у 1) – вероятность вытащить белый шар = ½; Р(у 2) – вероятность вытащить черный шар = ½; и, наконец, то, что мы ищем – Р(х 1 |у 1) – вероятность того, что верна первая гипотеза (оба шара белых), при условии, что мы вытащили белый шар (апостериорная вероятность или вероятность после опыта); Р(х 2 |у 1) – вероятность того, что верна вторая гипотеза (один шар белый, второй – черный), при условии, что мы вытащили белый шар.
Вероятность того, что верна первая гипотеза (два белых), при условии, что мы вытащили белый шар :

Вероятность того, что верна вторая гипотеза (один белый, второй – черный), при условии, что мы вытащили белый шар :

Вероятность того, что верна третья гипотеза (два черных), при условии, что мы вытащили белый шар :

Что делает формула Байеса? Она дает возможность на основании априорных вероятностей гипотез – Р(х 1), Р(х 2) , Р(х 3) – и вероятностей наступления событий – Р(у 1), Р(у 2) – подсчитать апостериорные вероятности гипотез, например, вероятность первой гипотезы, при условии, что вытащили белый шар – Р(х 1 |у 1) .
Вернемся еще раз к формуле (1). Первоначальная вероятность первой гипотезы была Р(х 1) = 1/3. С вероятностью Р(у 1) = 1/2 мы могли вытащить белый шар, и с вероятностью Р(у 2) = 1/2 – черный. Мы вытащили белый. Вероятность вытащить белый при условии, что верна первая гипотеза Р(у 1 |х 1) = 1. Формула Байеса говорит, что так как вытащили белый, то вероятность первой гипотезы возросла до 2/3, вероятность второй гипотезы по-прежнему равна 1/3, а вероятность третьей гипотезы обратилась в ноль.
Легко проверить, что вытащи мы черный шар, апостериорные вероятности изменились бы симметрично: Р(х 1 |у 2) = 0, Р(х 2 |у 2) = 1/3, Р(х 3 |у 2) = 2/3.
Вот что писал Пьер Симон Лаплас о формуле Байеса в работе , вышедшей в 1814 г.:
Это основной принцип той отрасли анализа случайностей, которая занимается переходами от событий к причинам.
Почему формула Байеса так сложна для понимания!? На мой взгляд, потому, что наш обычный подход – это рассуждения от причин к следствиям. Например, если в урне 36 шаров из которых 6 черных, а остальные белые. Какова вероятность вытащить белый шар? Формула Байеса позволяет идти от событий к причинам (гипотезам). Если у нас было три гипотезы, и произошло событие, то как именно это событие (а не альтернативное) повлияло на первоначальные вероятности гипотез? Как изменились эти вероятности?
Я считаю, что формула Байеса не просто о вероятностях. Она изменяет парадигму восприятия. Каков ход мыслей при использовании детерминистской парадигмы? Если произошло событие, какова его причина? Если произошло ДТП, чрезвычайное происшествие, военный конфликт. Кто или что явилось их виной? Как думает байесовский наблюдатель? Какова структура реальности, приведшая в данном случае к такому-то проявлению… Байесовец понимает, что в ином случае результат мог быть иным…
Немного иначе разместим символы в формулах (1) и (2):

Давайте еще раз проговорим, что же мы видим. С равной исходной (априорной) вероятностью могла быть истинной одна из трех гипотез. С равной вероятностью мы могли вытащить белый или черный шар. Мы вытащили белый. В свете этой новой дополнительной информации следует пересмотреть нашу оценку гипотез. Формула Байеса позволяет это сделать численно. Априорная вероятность первой гипотезы (формула 7) была Р(х 1) , вытащили белый шар, апостериорная вероятность первой гипотезы стала Р(х 1 |у 1). Эти вероятности отличаются на коэффициент .
Событие у 1 называется свидетельством, в большей или меньшей степени подтверждающим или опровергающим гипотезу х 1 . Указанный коэффициент иногда называют мощностью свидетельства. Чем мощнее свидетельство (чем больше коэффициент отличается от единицы), тем больше факт наблюдения у 1 изменяет априорную вероятность, тем больше апостериорная вероятность отличается от априорной. Если свидетельство слабое (коэффициент ~ 1), апостериорная вероятность почти равна априорной.
Свидетельство у 1 в = 2 раза изменило априорную вероятность гипотезы х 1 (формула 4). В то же время свидетельство у 1 не изменило вероятность гипотезы х 2 , так как его мощность = 1 (формула 5).
В общем случае формула Байеса имеет следующий вид:

х – случайная величина (набор взаимоисключающих гипотез), принимающая значения: х 1 , х 2 , … , х n . у – случайная величина (набор взаимоисключающих событий), принимающая значения: у 1 , у 2 , … , у n . Формула Байеса позволяет найти апостериорную вероятность гипотезы х i при наступлении события y j . В числителе – произведение априорной вероятности гипотезы х i – Р(х i ) на вероятность наступления события y j , если верна гипотеза х i – Р(y j |х i ). В знаменателе – сумма произведений того же, что и в числителе, но для всех гипотез. Если вычислить знаменатель, то получим суммарную вероятность наступления события у j (если верна любая из гипотез) – Р(y j ) (как в формулах 1–3).
Еще раз о свидетельстве. Событие y j
дает дополнительную информацию, что позволяет пересмотреть априорную вероятность гипотезы х
i
. Мощность свидетельства –  – содержит в числителе вероятность наступления события y j
, если верна гипотеза х
i
. В знаменателе – суммарная вероятность наступления события у
j
(или вероятность наступления события у
j
усредненная по всем гипотезам). у
j
выше для гипотезы x
i
, чем в среднем для всех гипотез, то свидетельство играет на руку гипотезе x
i
, увеличивая ее апостериорную вероятность Р(y j
|х
i
).
Если вероятность наступления события у
j
ниже для гипотезы x
i
, чем в среднем для всех гипотез, то свидетельство понижает, апостериорную вероятность Р(y j
|х
i
) для
гипотезы x
i
.
Если вероятность наступления события у
j
для гипотезы x
i
такая же, как в среднем для всех гипотез, то свидетельство не изменяет апостериорную вероятность Р(y j
|х
i
) для
гипотезы x
i
.
– содержит в числителе вероятность наступления события y j
, если верна гипотеза х
i
. В знаменателе – суммарная вероятность наступления события у
j
(или вероятность наступления события у
j
усредненная по всем гипотезам). у
j
выше для гипотезы x
i
, чем в среднем для всех гипотез, то свидетельство играет на руку гипотезе x
i
, увеличивая ее апостериорную вероятность Р(y j
|х
i
).
Если вероятность наступления события у
j
ниже для гипотезы x
i
, чем в среднем для всех гипотез, то свидетельство понижает, апостериорную вероятность Р(y j
|х
i
) для
гипотезы x
i
.
Если вероятность наступления события у
j
для гипотезы x
i
такая же, как в среднем для всех гипотез, то свидетельство не изменяет апостериорную вероятность Р(y j
|х
i
) для
гипотезы x
i
.
Предлагаю вашему вниманию несколько примеров, которые, надеюсь, закрепят ваше понимание формулы Байеса.
Задача 2. Два стрелка независимо друг от друга стреляют по одной и той же мишени, делая каждый по одному выстрелу. Вероятность попадания в мишень для первого стрелка равна 0,8, для второго - 0,4. После стрельбы в мишени обнаружена одна пробоина. Найти вероятность того, что эта пробоина принадлежит первому стрелку. .
Задача 3. Объект, за которым ведется наблюдение, может быть в одном из двух состояний: Н 1 = {функционирует} и Н 2 = {не функционирует}. Априорные вероятности этих состояний Р(Н 1) = 0,7, Р(Н 2) = 0,3. Имеется два источника информации, которые приносят разноречивые сведения о состоянии объекта; первый источник сообщает, что объект не функционирует, второй - что функционирует. Известно, что первый источник дает правильные сведения с вероятностью 0,9, а с вероятностью 0,1 - ошибочные. Второй источник менее надежен: он дает правильные сведения с вероятностью 0,7, а с вероятностью 0,3 - ошибочные. Найдите апостериорные вероятности гипотез. .
Задачи 1–3 взяты из учебника Е.С.Вентцель, Л.А.Овчаров. Теория вероятностей и ее инженерные приложения, раздел 2.6 Теорема гипотез (формула Байеса).
Задача 4 взята из книги , раздел 4.3 Теорема Байеса.
Формула Байеса :Вероятности P(H i) гипотез H i называют априорными вероятностями - вероятности до проведения опытов.
Вероятности P(A/H i) называют апостериорными вероятностями – вероятности гипотез H i , уточненных в результате опыта.
Пример №1
. Прибор может собираться из высококачественных деталей и из деталей обычного качества. Около 40% приборов собираются из высококачественных деталей. Если прибор собран из высококачественных деталей, его надежность (вероятность безотказной работы) за время t равна 0,95; если из деталей обычного качества - его надежность равна 0,7. Прибор испытывался в течение времени t и работал безотказно. Найдите вероятность того, что он собран из высококачественных деталей.
Решение.
Возможны две гипотезы: H 1 - прибор собран из высококачественных деталей; H 2 - прибор собран из деталей обычного качества. Вероятности этих гипотез до опыта: P(H 1) = 0,4, P(H 2) = 0,6. В результате опыта наблюдалось событие A - прибор безотказно работал время t. Условные вероятности этого события при гипотезах H 1 и H 2 равны: P(A|H 1) = 0,95; P(A|H 2) = 0,7. По формуле (12) находим вероятность гипотезы H 1 после опыта:
![]()
Пример №2
. Два стрелка независимо один от другого стреляют по одной мишени, делая каждый по одному выстрелу. Вероятность попадания в мишень для первого стрелка 0,8, для второго 0,4. После стрельбы в мишени обнаружена одна пробоина. Предполагая, что два стрелка не могут попасть в одну и ту же точку, найдите вероятность того, что в мишень попал первый стрелок.
Решение.
Пусть событие A - после стрельбы в мишени обнаружена одна пробоина. До начала стрельбы возможны гипотезы:
H 1 - ни первый, ни второй стрелок не попадет, вероятность этой гипотезы: P(H 1) = 0,2 · 0,6 = 0,12.
H 2 - оба стрелка попадут, P(H 2) = 0,8 · 0,4 = 0,32.
H 3 - первый стрелок попадет, а второй не попадет, P(H 3) = 0,8 · 0,6 = 0,48.
H 4 - первый стрелок не попадет, а второй попадет, P (H 4) = 0,2 · 0,4 = 0,08.
Условные вероятности события A при этих гипотезах равны:
После опыта гипотезы H 1 и H 2 становятся невозможными, а вероятности гипотез H 3 и H 4
будут равны:
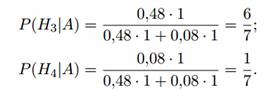
Итак, вероятнее всего, что мишень поражена первым стрелком.
Пример №3
. В монтажном цехе к устройству присоединяется электродвигатель. Электродвигатели поставляются тремя заводами-изготовителями. На складе имеются электродвигатели названных заводов соответственно в количестве 19,6 и 11 шт., которые могут безотказно работать до конца гарантийного срока соответственно с вероятностями 0,85, 0,76 и 0,71. Рабочий берет случайно один двигатель и монтирует его к устройству. Найдите вероятность того, что смонтированный и работающий безотказно до конца гарантийного срока электродвигатель поставлен соответственно первым, вторым или третьим заводом-изготовителем.
Решение.
Первым испытанием является выбор электродвигателя, вторым - работа электродвигателя во время гарантийного срока. Рассмотрим следующие события:
A - электродвигатель работает безотказно до конца гарантийного срока;
H 1 - монтер возьмет двигатель из продукции первого завода;
H 2 - монтер возьмет двигатель из продукции второго завода;
H 3 - монтер возьмет двигатель из продукции третьего завода.
Вероятность события A вычисляем по формуле полной вероятности:
Условные вероятности заданы в условии задачи:
Найдем вероятности
По формулам Бейеса (12) вычисляем условные вероятности гипотез H i:

Пример №4
. Вероятности того, что во время работы системы, которая состоит из трех элементов, откажут элементы с номерами 1, 2 и 3, относятся как 3: 2: 5. Вероятности выявления отказов этих элементов равны соответственно 0,95; 0,9 и 0,6.
б) В условиях данной задачи во время работы системы обнаружен отказ. Какой из элементов вероятнее всего отказал?
Решение.
Пусть А - событие отказа. Введем систему гипотез H1 - отказ первого элемента, H2 - отказ второго элемента, H3 - отказ третьего элемента.
Находим вероятности гипотез:
P(H1) = 3/(3+2+5) = 0.3
P(H2) = 2/(3+2+5) = 0.2
P(H3) = 5/(3+2+5) = 0.5
Согласно условию задачи условные вероятности события А равны:
P(A|H1) = 0.95, P(A|H2) = 0.9, P(A|H3) = 0.6
а) Найдите вероятность обнаружения отказа в работе системы.
P(A) = P(H1)*P(A|H1) + P(H2)*P(A|H2) + P(H3)*P(A|H3) = 0.3*0.95 + 0.2*0.9 + 0.5*0.6 = 0.765
б) В условиях данной задачи во время работы системы обнаружен отказ. Какой из элементов вероятнее всего отказал?
P1 = P(H1)*P(A|H1)/ P(A) = 0.3*0.95 / 0.765 = 0.373
P2 = P(H2)*P(A|H2)/ P(A) = 0.2*0.9 / 0.765 = 0.235
P3 = P(H3)*P(A|H3)/ P(A) = 0.5*0.6 / 0.765 = 0.392
Максимальная вероятность у третьего элемента.

